Acoustic signals, such as speech, are one of the most convenient communication means for human beings, and they offer universality in that everyone can use them bi-directionally. For this reason, acoustic signal processing has been an important research theme in the field of man-machine interfaces, such as videoconferencing systems, high-quality mobile phones, speech recognition/information retrieval/language translation, spoken dialogue robots, etc. Therefore, various industrial applications are expected to become available. However, in real environments, not only the target user speech but also miscellaneous interference sounds, background noise, etc. are observed at the same time, resulting in significant quality degradation of the output speech. In order to solve this problem, a flexible and practical statistical acoustic signal processing theory has been sought.
Blind Source Separation (BSS) based on Independent Component Analysis (ICA) (Fig. 1) has been in the spotlight because of the theoretical spread and the wide range of possibilities for applications. However, the technique of separating mixed speeches with the reverberation added in a room is a convolutive mixtures problem, hence it is difficult. When the award recipients initiated their research in 2000, study of this issue was only just beginning to be seen globally.
Blind source separation based on independent component analysis does not use any prior information, such as source environment and microphone position (hence the term "blind"). It is a theory of inverse estimation of the individual source signals. It can be regarded as simulating through information processing the human ability to subconsciously distinguish the individual source signal in the brain. Also, from an industrial perspective, the property of independent component analysis is very attractive because performance does not deteriorate (theoretically) even if microphone elements with many manufacturing errors are freely arranged. However, independent component analysis was just a mathematical optimization theory and there was no analytical and empirical analysis of its behavior. For this reason, independent component analysis and blind source separation, which have been discussed only statistically and mathematically, are some kind of black boxes physically and acoustically; nobody really knew what was done among them and how well we could separate the source signals.
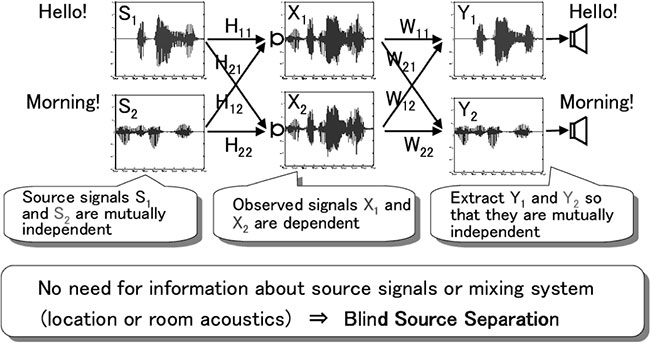
Fig. 1 Principle of blind source separation (BSS) based on independent component analysis (ICA). By making the output signals mutually independent, individual source signals are separated and extracted.
The award recipients analyzed the separation mechanism of blind source separation based on independent component analysis, which is an unsupervised learning theory based on higher order statistics, from the acoustic signal processing angle and clarified for the first time anywhere in the world that its operation principle is equivalent to parallel simultaneous learning of a microphone array, called a “beamformer.” Elucidation of this operation principle made it possible to use various acoustic signal processing techniques cultivated in the adaptive beamformer for audio source separation technology and, as a result, the researchers succeeded in greatly improving the separation performance of blind source separation technology. Notably, this work won both linear and nonlinear divisions in the IEEE International Workshop on Machine Learning for Signal Processing (MLSP) World Source Separation Contest in 2007, proving that a Japanese research group acting on behalf of the award recipients and operating on the global cutting edge, had the world's most powerful skills. Since then, the award recipients have led worldwide research in the field and established new research avenues. This result was implemented for the first time anywhere on general purpose DSP and general purpose PC (Fig. 2 (a), (b)). In addition, it came into practical use with the world's first real-time pocket-size audio source separation microphone, which was adopted as police equipment in 2008 (Fig. 2 (c)). In recent years, it has been adopted as an acoustic sensor in a snake-like robot for disaster rescue at the ImPACT Tough Robotics Challenge (Fig. 2 (d)).
These achievements have received high recognition; for example, a Commendation for Science and Technology by the Minister of MEXT (2015), Ichimura Science Awards (2013), Docomo Mobile Science Awards (2011), ICA Unsupervised Learning Pioneer Award (2006), IEEE Fellow (2004), IEICE Fellow (2007), etc. These achievements are extremely remarkable and fully deserving of the IEICE Achievement Award.
(a) World's first DSP version audio source separation device
(b) World's first audio source separation device for videoconferencing
(c) Police recruitment version audio source separation device
(d) Snake type robot for disaster relief
- S. Araki, R. Mukai, S. Makino, T. Nishikawa, H. Saruwatari, “The fundamental limitation of frequency domain blind source separation for convolutive mixtures of speech,” IEEE Trans. Speech Audio Processing, vol. 11, no. 2, pp. 109-116, 2003.
- S. Araki, S. Makino, Y. Hinamoto, R. Mukai, T. Nishikawa, H. Saruwatari, “Equivalence between frequency domain blind source separation and frequency domain adaptive beamforming for convolutive mixtures,” EURASIP Journal on Applied Signal Processing, vol. 2003, no. 11, pp. 1157-1166, 2003.
- H. Sawada, R. Mukai, S. Araki, S. Makino, “A robust and precise method for solving the permutation problem of frequency-domain blind source separation,” IEEE Trans. Speech Audio Processing, vol. 12, no. 5, pp. 530-538, 2004.
- H. Saruwatari, T. Kawamura, T. Nishikawa, A. Lee, K. Shikano, “Blind source separation based on a fast-convergence algorithm combining ICA and beamforming,” IEEE Trans. Speech and Audio Processing, vol. 14, no. 2, pp. 666-678, 2006.
- Y. Mori, H. Saruwatari, T. Takatani, S. Ukai, K. Shikano, T. Hiekata, Y. Ikeda, H. Hashimoto, T. Morita, “Blind separation of acoustic signals combining SIMO-model-based independent component analysis and binary masking,” EURASIP Journal on Applied Signal Processing, vol. 2006, Article ID 34970, 17 pages, 2006.
- S. Araki, H. Sawada, R. Mukai, and S. Makino, “Underdetermined blind sparse source separation for arbitrarily arranged multiple sensors,” Signal Processing, vol. 87, pp. 1833-1847, Feb. 2007.
- H. Sawada, S. Araki, R. Mukai, S. Makino, “Grouping separated frequency components by estimating propagation model parameters in frequency-domain blind source separation,” IEEE Trans. Audio, Speech and Language Processing, vol. 15, no. 5, pp. 1592-1604, 2007.
- Y. Takahashi, T. Takatani, K. Osako, H. Saruwatari, K. Shikano, “Blind spatial subtraction array for speech enhancement in noisy environment,” IEEE Trans. Audio, Speech and Language Processing, vol. 17, no. 4, pp. 650-664, 2009.
- H. Sawada, S. Araki, S. Makino, “Underdetermined convolutive blind source separation via frequency bin-wise clustering and permutation alignment,” IEEE Trans. Audio, Speech and Language Processing, vol. 19, no. 3, pp. 516-527, 2011.
- R. Miyazaki, H. Saruwatari, T. Inoue, Y. Takahashi, K. Shikano, K. Kondo, “Musical-noise-free speech enhancement based on optimized iterative spectral subtraction,” IEEE Trans. Audio, Speech and Language Processing, vol. 20, no.7, pp. 2080-2094, 2012.



